
Binary Tree
This is the most basic form of trees among all tree data structures in Computer Science. The topmost node is called Root, and each node has utmost two children – left child and right child. Nodes with no children are called Leaves. Binary Trees are widely used in computer science for various applications like searching, sorting, and hierarchical representation.
A full binary tree is the one in which all interior nodes have either zero or two children. A perfect binary tree is the one in which all interior nodes have two children and all leaves have the same level of depth. In a complete binary tree every level, except possibly the last, is completely filled, and all nodes in the last level are as far left as possible.
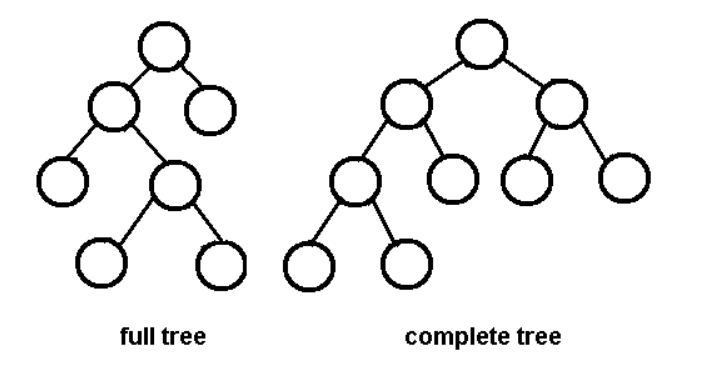
In a binary tree, nodes are inserted without any specific order. So, a full tree traversal may be needed (like an array) to find a node. So, the time complexity is O(n) for insertion, deletion, and search. A binary tree could become unbalanced and inefficient as you do more and more operations.
Binary Search Tree
A binary search tree is a binary tree with special properties. All the nodes to the left have lesser value than the parent node and all nodes to the right have greater value than the parent node. Any new additions to the tree are done accordingly so as to maintain this property of the binary search tree. Each node contains one key (or also called data) and two children – left and right.
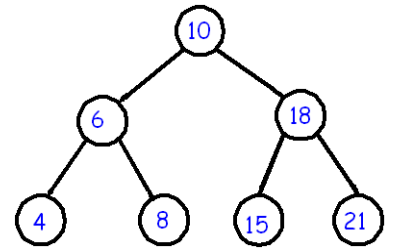
Because of this special property of binary search trees, the time complexity of insertions, search, and deletions comes down to O(h), where ‘h’ is the height of the tree. Isn’t that beautiful? Imagine coming down from O(n) to O(h), such an incredible efficiency because of the way in which we order the binary search tree
B-trees
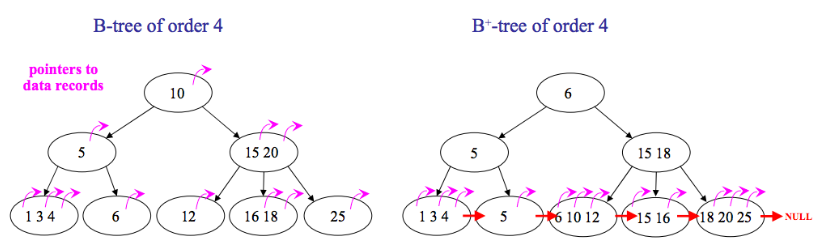
B-Trees are a variation on binary search trees that allow quick searching in files on disk. Instead of storing one key and having two children, B-tree nodes have n keys and n+1 children, where n can be large. This shortens the tree (in terms of height) and requires much less disk access than a binary search tree would. The algorithms are a bit more complicated, requiring more computation than a binary search tree, but this extra complication is worth it because computation is much cheaper than disk access.
A B-Tree has the space complexity equal to O(n), and it has the insertion and deletion time complexity equal to O(log n).
In a B-Tree of order m, there are three types of nodes with the following properties

B+ Tree
The B+ tree is also a self-balancing tree just as the B-tree. But, the major difference is that B-tree holds both keys and data in the internal and leaf nodes. Whereas in the B+ tree, the data is only held by the leaf nodes. So, what is the advantage of it?
Advantages of B+ trees:
- Because B+ trees don’t have data associated with interior nodes, more keys can fit on a page of memory. Therefore, it will require fewer cache misses in order to access data that is on a leaf node.
- The leaf nodes of B+ trees are linked, so doing a full scan of all objects in a tree requires just one linear pass through all the leaf nodes. A B tree, on the other hand, would require a traversal of every level in the tree. This full-tree traversal will likely involve more cache misses than the linear traversal of B+ leaves.
Advantage of B trees:
- Because B trees contain data with each key, frequently accessed nodes can lie closer to the root, and therefore can be accessed more quickly.
Hope this helps as a basic primer on various tree data structures, thank you.
You may like to read: How Coding & Math are complimentary?, What is Coding for Kids?, & Encryption explained to young students