
Encoding is the process of assigning codes or numbers to the characters in a written language used for communication. So, if you think you will use English as a means of communication, then you will assign codes to the alphabet and use it as a means to communicate. The objective of this encoding exercise is to ensure that the recipient is receiving the message in the right way as you intend as the recipient decodes using the same codes (or code set).
American Standard Code for Information Interchange (ASCII) was the first major encoding system. Originally, the ASCII system could incorporate 128 characters, primarily because it was designed to incorporate only the English alphabet and some other special characters that are used in the English language such as numbers, punctuation, and other characters. The ASCII system used 7 bits to represent each character. So, the maximum number of characters it could represent was 128 characters. The 8th bit (MSB) was always set to zero. But in the modern version, the 8th bit is set to 1 and it added another 128 characters, and hence totalling to 256 characters overall. So, ASCII today represents or encodes 256 characters. So, each character, for example alphabet ‘A’ is represented as an 8 bit code.
The table below shows the ASCII characters encoded from 0 to 127 (the first 128 characters). 65 to 90 and 97 to 122 represent the alphabets. It also contains many non-alphanumeric characters. Extended ASCII is the 128 to 255 which contains special characters, accented letters, and art characters.
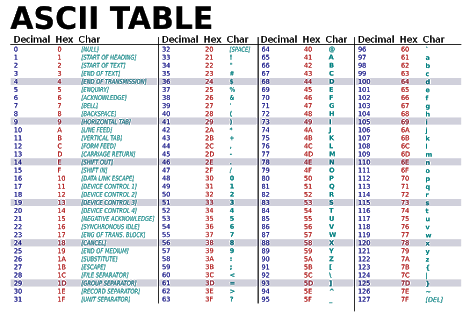
But, all is not well with ASCII. The problem with ASCII is it can only be used to encode English communications. If you want to use Japanese, Hindi, Chinese or other languages in your email ,then it couldn’t accommodate the character sets of these languages.
This led to the invention of the Unicode Transformation Format (UTF). UTF comes in three forms – UTF-8, UTF-16 and UTF-32. You guessed it, UTF-8 uses 8 bits, UTF-16 uses 16 bits, and UTF-32 uses 32 bits.
Now, you must be thinking that if Extended ASCII is 8 bits and UTF-8 is also 8 bits, how can UTF-8 accommodate more characters than 256. Will it not have the same issue as ASCII?
UTF-8 doesn’t mean it only uses 8 bits. UTF-8 means the minimum it uses is 1 byte (8 bits) but if required it can extend up to 4 bytes (32 bits). So, UTF-8 can accommodate more than a million characters. Similarly, when we say UTF-16, the minimum bytes used by UTF-16 is 2 bytes (16 bits) but it can extend up to 4 bytes (32 bits).
Obviously, we want to also save space and ensure the size of files are efficient. Therefore, the most widely used encoding system of the Internet is the UTF-8. It is also backward compatible with ASCII (8 bit codes). With all these advantages and its widespread use, UTF is called as the Queen of Encoding Systems.
Hope this is useful to provide an idea on Encoding, thank you.
You may like to read: How Coding & Math Are Complementary?, Top 10 Most Popular Roblox Games, and How to make a character jump in Scratch?


